理解svg中画箭头代码[viewbox,refX,refY]
2014年7月09日 20:52
常见示例
最常见的在线条上画箭头代码
<svg>
<!-- 预定义marker-->
<defs>
<marker id="arrow" refX="0" refY="3" markerWidth="20" markerHeight="20" orient="auto">
<path d="M0 0 L0 6 L10 3" style="fill: #ffff;"></path>
</marker>
</marker>
</defs>
<!-- 引用预定义的marker -->
<line class="link" marker-end="url(#arrow)" x1="0" y1="0" x2="80" y2="80"></line>
</svg>
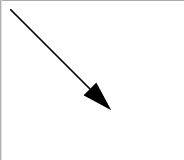
先预定义了一个箭头形状的marker,然后画了一条线,并且将预定义的marker标到线条末端.
画出的图形

实现方法是用path画一个三角形并填充到marker中,形成三角marker,之所以用marker是因为,只有marker才能标到其它图形上. 但是marker是怎样被标记线条末端的?在marker中有refX、refY作用就是用来指定线条末点连接到marker上的位置. 连接上后,箭头指向哪边?orient属性则指定marker的方向.
如何为marker中坐标取值
首先marker与包含的path共用一个坐标系,如果坐标值不对则会显示不全.
比如上面marker的显示范围是(0,0)到(20, 20), path的范围是(0,0)到(10,6),可知道path完全处在marker的显示区域内,因此path可以全部显示.
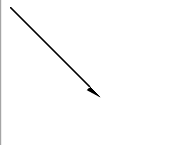
如果需改path值,path显示范围为(0,-3)到(10,3),有一半内容在marker显示区域外,我们看到的就是半个三角形。设置坐标时要知道marker与path是共用同一个坐标系,path坐标不是相对于marker,注意path要在marker的可视范围内
<svg>
<!-- 预定义marker-->
<defs>
<marker id="arrow" refX="0" refY="0" markerWidth="20" markerHeight="20" orient="auto">
<path d="M0 -3 L0 3 L10 0" style="fill: #ffff;"></path>
</marker>
</marker>
</defs>
<!-- 引用预定义的marker -->
<line class="link" marker-end="url(#arrow)" x1="0" y1="0" x2="80" y2="80"></line>
</svg>
如下
理解marker的viewBox属性
用法viewBox(xmin, ymin, width, height)
查看文档可知道viewBox作用是拉伸图形。它是如何控制拉伸的?要想拉伸的话,指定长宽比例就可以了,怎么会用到xmin, ymin, width, height这些值,它们是和拉伸有什么关系?怎么理解?
实际上拉伸只是它的一个功能,换一种叫法就很好理解: 取景框. 它使用xmin,ymin,width,height这些参数确定取景范围,然后将取到的景象,放到marker中,并且充满整个marker. 如果取到的景象比marker可视范围小,则景象会被放大再充满marker;如果取到的景象比marker可视范围大,怎取景会被缩小再充满marker. 所以viewbox有两个功能:一是填充功能;二是拉伸.
比如上面只显示半个三角形,可以通过设置viewbox让它,在marker中完整显示.
<svg>
<!-- 预定义marker-->
<defs>
<marker id="arrow" refX="0" refY="0" markerWidth="20" markerHeight="20" orient="auto" viewBox="0, -3, 10, 6" >
<path d="M0 -3 L0 3 L10 0" style="fill: #ffff;"></path>
</marker>
</marker>
</defs>
<!-- 引用预定义的marker -->
<line class="link" marker-end="url(#arrow)" x1="0" y1="0" x2="80" y2="80"></line>
</svg>
上面viewBox控制了取景范围,正好将整个三角形取出来,再放入长20宽20的marker中,因为viewbox取到的景象长为10宽为6,小于marker大小,要想让三角形充满,则要放大景象,放大的比例长为20/10,宽为20/6.
显示结果